Parallel Computing Architecture
Flynn’s Classical Taxonomy
Flynn’s Taxonomy is a widely used classification system for parallel computers, first introduced in 1966. It categorizes parallel computer architectures based on two independent dimensions: Instruction and Data, each having two possible states: Single or Multiple.
Flynn Taxonomy - Categories:
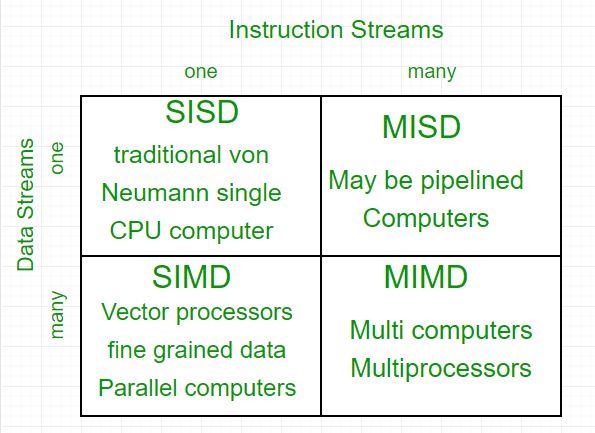
Taxonomy of Parallel Processor Architectures:
Single Instruction, Single Data (SISD)

- Uniprocessor
- Single processor
- Single instruction
- Single memory
Description:
- This is a serial (non-parallel) computer architecture.
- It operates with a single instruction and a single data stream during each clock cycle.
- Execution is deterministic.
- Examples: Most personal computers, single CPU workstations, and mainframes.
Single Instruction, Multiple Data (SIMD)
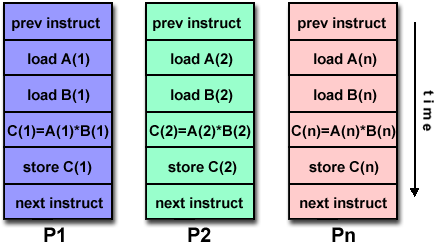
- Single instruction controls simultaneous execution of Processing Elements (PE).
- Different PEs process different data.
- Vector and array processor
Description:
- This architecture type executes the same instruction across all processing units during each clock cycle.
- Each processing unit can operate on a different data element.
- Suited for problems with a high degree of regularity, such as image processing.
- Synchronous (lockstep) and deterministic execution.
- Two varieties: Processor Arrays and Vector Pipelines.
- Examples: Processor Arrays (Connection Machine CM-2, Maspar MP-1, MP-2), Vector Pipelines (IBM 9000, Cray C90, Fujitsu VP, NEC SX-2, Hitachi S820).
Multiple Instruction, Single Data (MISD)
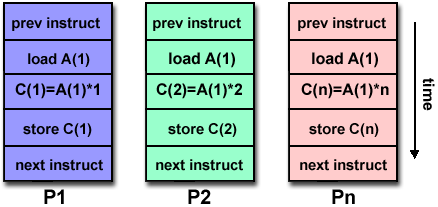
- Same data, different processors
- Different instruction
Description:
- In this architecture, a single data stream is fed into multiple processing units.
- Each processing unit operates on the data independently via independent instruction streams.
- Few actual examples exist, with one being the experimental Carnegie-Mellon C.mmp computer (1971).
- Possible applications include multiple frequency filters operating on a single signal stream or multiple cryptography algorithms attempting to crack a single coded message.
Multiple Instruction, Multiple Data (MIMD)
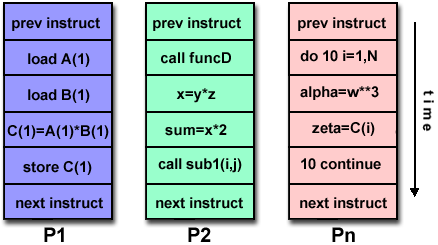
- Different instruction
- Different data
- Different processors
- Applies to Symmetric Multiprocessor (SMP), Nonuniform Memory Access (NUMA), and Clusters
Description:
- This is the most common type of parallel computer architecture.
- Multiple processors may execute different instruction streams and work with different data streams.
- Execution can be synchronous or asynchronous, deterministic or non-deterministic.
- Examples include most current supercomputers, networked parallel computer “grids,” and multiprocessor SMP computers, including some types of PCs.
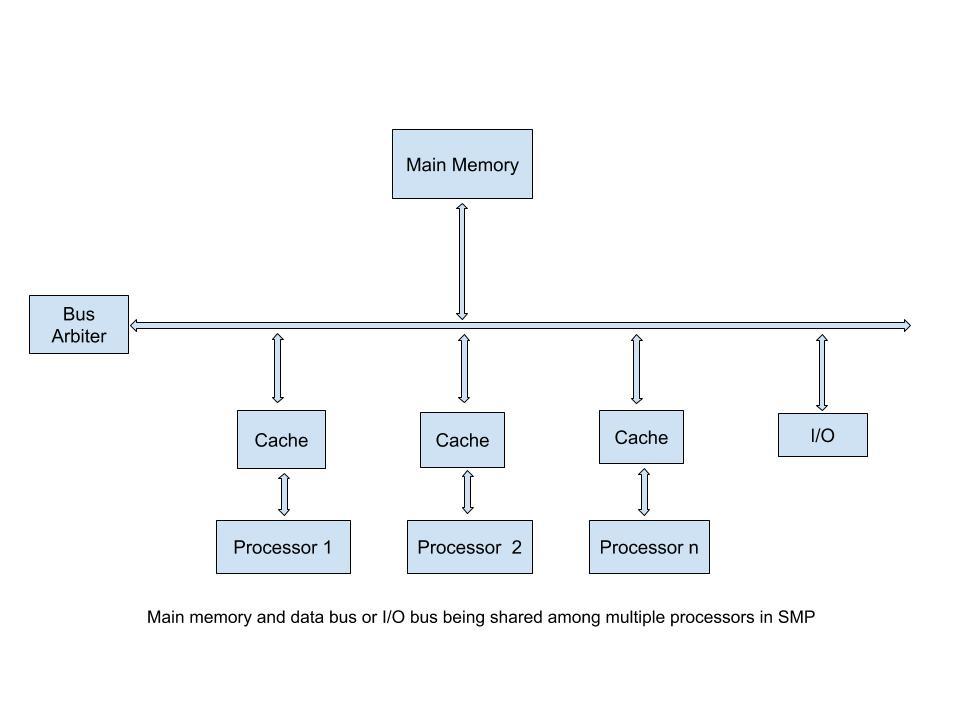
Shared Memory
Symmetric Multiprocessor (SMP)
- Two or more similar processors of comparable capability (identical processors)
- Uniformed Memory Access (UMA)
- All processors share connection to memory and I/O devices
- Perform the same functions
- Equal access and equal access time to memory
- Controlled by an integrated OS
- Cache coherent
Advantages:
- Improved performance through parallel processing.
- High availability; failure of a single processor does not halt the machine.
- Flexibility and incremental growth by adding additional processors.
- Scalability with a range of products offering different price and performance characteristics.
Organization:
Key design issues:
- Simultaneous concurrent processes, with the OS enabling parallel execution.
- Scheduling to avoid conflicts between processes.
- Synchronization to enforce mutual exclusion and event ordering, preventing conflicts in memory access.
- Memory management, including paging.
- Reliability and fault tolerance, with the OS handling degradation caused by processor failure.
Nonuniform Memory Access (NUMA)
NUMA (Nonuniform Memory Access) is a parallel computing architecture often created by physically linking two or more SMPs (Symmetric Multiprocessors). In NUMA, all processors have access to all parts of main memory, but the access time depends on the location of the memory.
Characteristics:
- Maintains a transparent system-wide memory view with multiple processor nodes.
- One SMP can directly access the memory of another SMP.
- Not all processors have equal access times to all memory locations.
- When cache coherency is maintained, it is known as Cache Coherent NUMA (CC-NUMA).
- Cache coherence is maintained among caches of different processors.

Design Issues:
- Overloaded memory access to remote nodes.
- Additional nodes introduce additional traffic.
Solutions:
- Use L1 and L2 caches to minimize memory access.
- Implement software techniques to ensure good spatial locality (virtual memory).
- Employ OS-based page migration to manage memory effectively.
Pros:
- High performance with minimal software changes.
Cons:
- Not as transparent as SMP, requiring software changes.
- Availability concerns due to complexity.
Distributed Memory
Distributed Memory is an approach where a group of interconnected computers work together as a unified computing resource. Each computer in the cluster operates independently and has its own local memory, which is not shared. CPUs in this architecture need explicit access to data in other processors, which must be defined by the programmer.
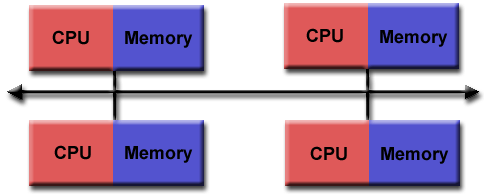
Advantages:
- Memory scales with the number of processors.
- Offers absolute scalability, often better than standalone machines.
- Incremental scalability allows for adding new nodes.
- High availability; failure in one node doesn’t impact the entire system.
- Provides superior price/performance by adding computing power at a lower cost.
- Each processor can access its local memory rapidly without interference.
Disadvantages:
- Increased complexity for programmers in terms of data arrangement.
- Mapping existing data structures can be challenging based on global memory.
- Non-uniform memory access times, with data on remote nodes taking longer to access than local data.
Cluster Configuration
Clusters can be configured in various ways:
-
Standby server with no shared disk: Two-node interconnected setup with high-speed links, LAN, and WAN communication.
-
Shared disk: Two-node interconnected setup with high-speed links, LAN, WAN communication, and a disk subsystem such as a RAID system.
Clustering Methods:
-
Passive Standby: One computer handles all processing load, with the other taking over only in the event of failure. “Heartbeat” messages are sent from the primary machine to standby machines, increasing availability but not performance.
-
Active Secondary: Separate servers actively process tasks and are connected to disks. Servers share access to these disks.
Clusters compared to SMP:
| Characteristic | Clusters | SMP (Symmetric Multiprocessor) |
|---|---|---|
| Number of Processors | Multiple processors | Multiple processors |
| Configuration | Need to deal with different computer range and specifications | Easier to manage and configure |
| Physical Space | More space to allocate to each node | Located on computer motherboard |
| Power Consumption | Power required by each node | Power required by each processor |
| Stability | Not stable – depends on connection and node’s availability | Stable and established |
| Scalability | Big and expandable | Small-scale/single computing |
Hybrid Distributed Shared Memory
This architecture applies both shared and distributed memory architectures. It combines a shared memory component (such as a shared memory machine or GPUs) with a distributed memory component (networking of multiple shared memory/GPU machines). Each node in the distributed memory component only knows about its own memory, and network communication handles data transfer between nodes.